Sticky No More: New Algorithm Helps Scientists Reduce Protein Aggregation
Proteins are the silent engines of modern life. They help make life-saving medicines, break down environmental pollutants, improve our food, and power industrial processes. Nevertheless, there is a catch: many proteins have a stubborn tendency to stick together, forming useless clumps that render them inactive. This frustrating behaviour has been holding back science until now.
To address this challenge, researchers from the International Clinical Research Center (ICRC-FNUSA) and Masaryk University (MU), in collaboration with IT4Innovations National Supercomputing Center at VSB – Technical University of Ostrava, developed a machine-learning-based algorithm for fast and reliable detection of the sticky regions that drive protein aggregation. Their identification allows the researchers to design changes into these regions that prevent proteins from sticking together, enabling their more efficient use in real-world applications. To demonstrate the approach, scientists from the Loschmidt Laboratories dramatically improved the production quality and yield of an enzyme that degrades toxic man-made chemicals in the environment. The method has been described in a recent article published in a leading scientific journal Communications Chemistry: Experimentally validated deep learning control of protein aggregations.
Additionally, using their software, the researchers from ICRC-FNUSA, MU, and IT4Innovations identified and experimentally validated errors in widely used databases used to train similar algorithms. “Computer algorithms are increasingly accelerating research. However, their efficiency depends on the quality of the data used for their training. Our study significantly contributes to improving the reliability of these datasets and, consequently, the accuracy of future predictive tools,” says Antonin Kunka, one of the authors leading the experimental validation of the software.
”It was a pleasure to be part of the team that developed and experimentally validated the deep neural network-based predictor AggreProt, which can help researchers identify aggregation-prone regions in proteins and design mutations that suppress protein aggregation,” says Jan Martinovic from IT4Innovations. “The study demonstrated that the approach can substantially improve protein solubility and significantly increase production yields, opening new possibilities for biotechnology, environmental applications, and medicine. The project also revealed inaccuracies in existing aggregation databases, contributing to the development of more reliable AI-driven predictive methods in protein science.“
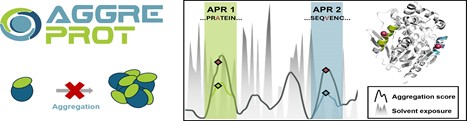
This figure illustrates the AggreProt tool for analyzing protein aggregation, showing how certain sequences or regions of a protein relate to aggregation propensity and solvent exposure.
“The experimental validation demonstrates the great accuracy of our tool, AggreProt, in identifying the aggregation-prone regions in proteins,” adds Joan Planas-Iglesias from the Loschmidt Laboratories at MU and ICRC of St. Anne’s University Hospital in Brno, and the Faculty of Medicine of MU, who led the development of the software algorithm and coordinated the collaboration between biologists and computer scientists. “AggreProt is now accessible to the wider scientific community, enabling researchers to improve the production of proteins important for biotechnology, environmental applications, and medicine.”
The collaboration between computational and experimental biologists from MU and the ICRC-FNUSA and researchers from IT4Innovations highlights the importance of cross-institutional collaboration across different fields in driving world-class research.
Availability:
- Publication:
https://www.nature.com/articles/s42004-026-02007-5
- Publication introducing AggreProt webserver:
https://academic.oup.com/nar/article/52/W1/W159/7683054
- AggreProt web server: https://loschmidt.chemi.muni.cz/aggreprot/
Contacts:
- Antonin Kunka, Postdoctoral Researcher at Protein Biophysics Group, Department of Biotechnology and Biomedicine, Technical University of Denmark. antkun@dtu.dk
- Joan Planas-Iglesias, Researcher at the Faculty of Science, Masaryk University and International Clinical Research Centre of St. Anne’s University Hospital in Brno, and the Faculty of Medicine of MU – joan.planas@mail.muni.cz
- Jan Martinovic, Head of the Advanced Data Analysis and Simulations Lab of IT4Innovations National Supercomputing Center, VSB – Technical University of Ostrava – jan.martinovic@vsb.cz
This work was supported by the CLARA project – The European Union’s Horizon Europe research and innovation programme under grant agreement No. 101136607. This project is co-funded by the European Union in the Center for Artificial Intelligence and Quantum Computing in System Brain Research project (CZ.02.01.01/00/23_029/0008437) under the OP JAC.
